Harbor multi datacenter with replicated artifacts
Chez Veepee, où je travaille en tant que lead SRE en 2023, nous avons commencé à travailler sur notre prochaine génération de registry d’artefacts pour Docker (et Helm).
Actuellement, nous utilisons Artifactory en tant que registry pull (avec mise en cache des repos publics) et push depuis nos orchestrateurs et notre CI/CD. Cette configuration est limitée à un seul datacenter, les licences Artifactory nous limitant en termes de déploiement. De plus le réseau privé distribué (PDN) d’Artifactory est très intéressant, mais trop coûteux pour nous.
En termes d’hébergement, nous utilisons plusieurs datacenters et dans plusieurs pays mais nous téléchargons tout depuis un unique datacenter. C’est clairement sous-optimal, que ce soit en termes de latence ou d’utilisation de la bande passante, au dela du fait que ce soit également un SPOF. Notre modèle d’hébergement au sein d’un datacenter est très solide néanmoins nous souhaitons améliorer la situation en ayant un registry local dans chaque datacenter et répliquer les artefacts entre chaque.
C’est ici qu’intervient Harbor. Il s’agit un projet CNCF open source et natif pour Kubernetes. Il dispose également d’un déploiement via docker-compose, ce qui nous intéresse pour nos datacenters en PRA.
Harbor est composé de plusieurs composants :
- core : API de Harbor
- portal : interface utilisateur de Harbor
- registry : registre Docker
- chartmuseum : registry Helm (sera déprécié au profit du registre OCI)
- notary : registry de signatures
- trivy : scanner de vulnérabilités
Chaque partie peut être activée ou désactivée. Sur nos centres de données principaux, nous les activerons tous, mais sur le centre de données DRP, nous n’activerons que le registre et le portail pour pouvoir parcourir les artefacts.
Architecture
Voici le modèle de déploiement que nous avons choisi en fonction du type de datacenter :
- Datacenter principal : Tous les services, avec un stockage S3 sur Ceph et PostgreSQL avec Patroni (2 nœuds)
- Datacenter PRA : Seulement le registre et le portail, avec un stockage local et PostgreSQL avec Patroni (nœud unique)
Voici le schéma d’architecture global :
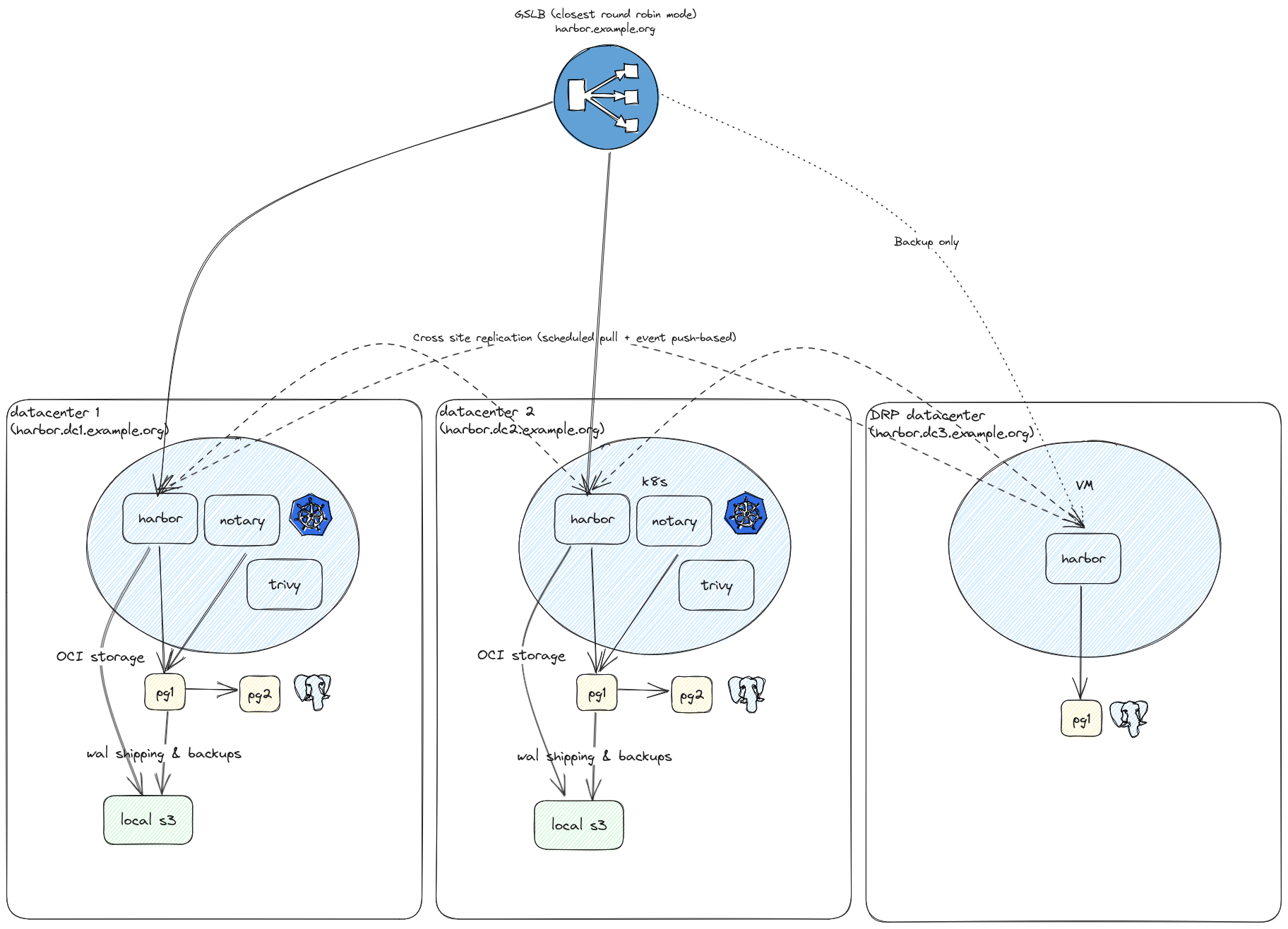
Déploiement
Dans les datacenters principaux, nous utilisons la chart Helm officiel et avons ajouté des HorizontalPodAutoscalers sur les déploiements core, registry et trivy afin de supporter une charge plus élevée. Nous avons des milliers d’utilisateurs et plusions millions d’artefacts.
Dans les datacenters secondaires, nous avons utilisé l’outil docker-compose officiellement prise en charge.
Chaque instance de Harbor fonctionne avec sa propre URL, représentée sous la forme suivante: harbor.<datacenter>.example.org.
Nous configurons ensuite notre GSLB pour avoir une seule URL de service pour tous les datacenters comme suit: harbor.example.org.
En terme de topologie, nous configurons nos datacenters principaux comme actifs et les datacenters PRA comme backup (appelés si tous les autres échouent).
Nous choisissons l’algorithme twrr, signifiant que le GSLB sélectionnera le datacenter fonctionnel le plus proche. Je ne détaillerai pas la configuration du GSLB,
c’est une configuration interne basée sur PowerDNS, mais vous pouvez obtenir le même résultat
sur n’importe quel fournisseur de cloud public.
Configuration
Maintenant que nous disposons d’un Harbor autonome dans chaque datacenters, il est temps de les configurer.
Nous utilisons Vault pour stocker les secrets et le provider Terraform officiel de Harbor.
terraform {
backend "s3" {}
required_providers {
harbor = {
source = "goharbor/harbor"
version = "3.9.4"
}
}
}
data "vault_generic_secret" "harbor" {
path = "secret/<amazing vault backed harbor secret>"
}
Configurons nos variable, le provider Harbor et la configuration OIDC pour nos utilisateurs finaux.
variable "datacenter" {
description = "Datacenter name"
}
variable "oidc_endpoint" {
description = "OIDC endpoint"
type = string
}
variable "multidc_replicated_repository" {
type = map(any)
default = {}
}
variable "harbor_url" {
description = "Harbor URL"
type = string
}
variable "harbor_remotes" {
description = "harbor remote instances"
type = map(string)
}
provider "harbor" {
url = var.harbor_url
username = data.vault_generic_secret.harbor.data["admin-user"]
password = data.vault_generic_secret.harbor.data["admin-password"]
}
resource "harbor_config_auth" "keycloak" {
auth_mode = "oidc_auth"
oidc_name = "keycloak"
oidc_endpoint = var.oidc_endpoint
oidc_client_id = data.vault_generic_secret.harbor.data["oidc-client-id"]
oidc_client_secret = data.vault_generic_secret.harbor.data["oidc-client-secret"]
oidc_scope = "openid"
oidc_verify_cert = true
oidc_auto_onboard = true
oidc_user_claim = "preferred_username"
oidc_groups_claim = "roles" // doesn't seems to work
oidc_admin_group = "sre"
}
Réplication entre datacenters
Maintenant que notre Harbor est configuré globalement, nous voulons avoir des dépôts locaux répliqués sur chaque datacenter.
Le mode pull est intéressant, mais il est planifié. Cela signifie que si vous poussez un artefact sur un datacenter, il ne sera pas
disponible immédiatement sur les autres datacenters, en fonction de la planification définie. Cela peut être ennuyeux si vous êtes
en train de pousser un artefact depuis un datacenter et de le déployer sur un autre.
La solution est de combiner les deux, afin de garantir la synchronisation du dépôt et la publication des artefacts récents. Nous
choisissons ici de répliquer en mode pull l’ensemble du dépôt toutes les 15 minutes.
Ici, nous créons une simple map de dépôts, préfixée par multi-dc afin de l’identifier directement dans l’interface utilisateur.
Chaque dépôt a un quota par défaut de 10 Go et un compte robot dédié avec des droits de pull et de `push. Nous mettons également
en place une politique de rétention afin d’éviter une croissance infinie. Ici, il sera gardé s’il a été récupéré dans les 180 derniers jours
ou s’il fait partie des 10 plus récents.
locals {
replicated_registries = merge([
for krepo, vrepo in var.multidc_replicated_repository : {
for k, v in var.harbor_remotes :
k => {
"name" : krepo,
"endpoint_url" : v,
"description" : "${krepo} ${k} remote",
} if k != var.datacenter
}]...)
}
resource "harbor_registry" "multi-dc-replicated" {
for_each = local.replicated_registries
provider_name = try(each.value.provider, "harbor")
name = "multi-dc-${each.value.name}-${each.key}"
endpoint_url = each.value.endpoint_url
description = each.value.description
access_id = "robot$multi-dc-${each.value.name}+${harbor_robot_account.multi-dc-replication-robot[each.value.name].name}"
access_secret = data.vault_generic_secret.harbor.data["robot-password/replication/${each.value.name}"]
}
resource "harbor_project" "multi-dc-replicated" {
for_each = var.multidc_replicated_repository
name = "multi-dc-${each.key}"
public = false
storage_quota = try(each.value.storage_quota, 10)
}
resource "harbor_retention_policy" "multi-dc-replicated" {
for_each = var.multidc_replicated_repository
scope = harbor_project.multi-dc-replicated[each.key].id
schedule = "Daily"
rule {
n_days_since_last_pull = 180
repo_matching = "**"
tag_matching = "**"
}
rule {
most_recently_pulled = 10
repo_matching = "**"
tag_matching = "**"
}
rule {
n_days_since_last_push = 180
repo_matching = "**"
tag_matching = "**"
}
}
// This robot account is to give to end users for read-only
resource "harbor_robot_account" "multi-dc-readonly-robot" {
for_each = var.multidc_replicated_repository
name = "readonly"
description = "Multi DC replication user for ${each.key} repository (configured with Terraform)"
level = "project"
secret = data.vault_generic_secret.harbor.data["robot-password/readonly/${each.key}"]
permissions {
access {
action = "pull"
resource = "repository"
}
kind = "project"
namespace = harbor_project.multi-dc-replicated[each.key].name
}
}
// This robot account is to give to end users for read-write
resource "harbor_robot_account" "multi-dc-readwrite-robot" {
for_each = var.multidc_replicated_repository
name = "readwrite"
description = "Multi DC replication user for ${each.key} repository (configured with Terraform)"
level = "project"
secret = data.vault_generic_secret.harbor.data["robot-password/readwrite/${each.key}"]
permissions {
access {
action = "pull"
resource = "repository"
}
access {
action = "push"
resource = "repository"
}
kind = "project"
namespace = harbor_project.multi-dc-replicated[each.key].name
}
}
// This robot account is to replicate images between registries
resource "harbor_robot_account" "multi-dc-replication-robot" {
for_each = var.multidc_replicated_repository
name = "sync"
description = "Multi DC replication user for ${each.key} repository (configured with Terraform)"
level = "project"
secret = data.vault_generic_secret.harbor.data["robot-password/replication/${each.key}"]
permissions {
// See https://github.com/goharbor/harbor/wiki/How-to-do-replication-with-Robot-Account
access {
action = "pull"
resource = "repository"
}
access {
action = "push"
resource = "repository"
}
access {
action = "list"
resource = "repository"
}
access {
action = "list"
resource = "artifact"
}
kind = "project"
namespace = harbor_project.multi-dc-replicated[each.key].name
}
}
resource "harbor_replication" "multi-dc-replication-pull" {
for_each = local.replicated_registries
name = "multi-dc-${each.value.name} from ${each.key}"
action = "pull"
registry_id = harbor_registry.multi-dc-replicated[each.key].registry_id
schedule = "0 0/15 * * * *"
dest_namespace = "multi-dc-${each.value.name}"
dest_namespace_replace = -1
filters {
name = "**"
}
filters {
tag = "**"
}
}
resource "harbor_replication" "multi-dc-replication-push" {
for_each = local.replicated_registries
name = "multi-dc-${each.value.name} to ${each.key}"
action = "push"
registry_id = harbor_registry.multi-dc-replicated[each.key].registry_id
schedule = "event_based"
dest_namespace = "multi-dc-${each.value.name}"
dest_namespace_replace = -1
filters {
name = "**"
}
filters {
tag = "**"
}
}
Maintenant, nous pouvons créer facilement nos dépôts multi dc sur chaque instance dans les tfvars:
multidc_replicated_repository = {
"repo1" = {}
"repo2" = {}
}
Mettre en cache certains dépôts publics
Maintenant que nous avons des registres privés, il peut être souhaitable de mettre en cache les images publiques en interne afin d’éviter de les télécharger depuis Internet chaque fois que nous en avons besoin.
Le code suivant déclare des registres distants préfixés par cache-, un quota de 1 To et une politique de rétention de 30 jours depuis
le dernier téléchargement.
variable "docker_upstream_cached_registries" {
type = map(any)
}
resource "harbor_registry" "docker" {
for_each = var.docker_upstream_cached_registries
provider_name = try(each.value.provider, "docker-registry")
name = each.key
endpoint_url = each.value.endpoint_url
description = try(each.value.description, null)
access_id = try(local.cache_registry_credentials[each.key].username, null)
access_secret = try(local.cache_registry_credentials[each.key].password, null)
}
resource "harbor_project" "public-cache" {
for_each = var.docker_upstream_cached_registries
name = "cache-${each.key}"
public = false
storage_quota = try(each.value.storage_quota, 1024)
registry_id = harbor_registry.docker[each.key].registry_id
}
resource "harbor_retention_policy" "public-cache" {
for_each = var.docker_upstream_cached_registries
scope = harbor_project.public-cache[each.key].id
schedule = "Daily"
rule {
n_days_since_last_pull = 30
repo_matching = "**"
tag_matching = "**"
}
rule {
n_days_since_last_push = 30
repo_matching = "**"
tag_matching = "**"
}
}
Configurons maintenant les tfvars:
docker_upstream_cached_registries = {
"dockerhub" = {
provider = "docker-hub"
endpoint_url = "https://hub.docker.com"
description = "Public Docker hub"
storage_quota = 2048
}
"quay.io" = {
endpoint_url = "https://quay.io"
description = "Public Quay.io"
storage_quota = 100
}
"gcr.io" = {
endpoint_url = "https://gcr.io"
description = "Public Google repository"
storage_quota = 10
}
"ghcr.io" = {
endpoint_url = "https://ghcr.io"
description = "Public GitHub repository"
storage_quota = 100
}
}
Répliquer certaines images de dépôt public
La mise en cache est très intéressante, mais nous pouvons imaginer certaines images très sensibles que nous voudrions toujours avoir localement, et ce, même si le registre amont est en panne. Pour cela, nous pouvons utiliser la réplication. C’est une fonctionnalité puissante de Harbor permettant de sélectionner des images en fonction de critères pour les répliquer localement.
Configurons un nouveau projet avec une politique de rétention d’un an et répliquons toutes les images basées sur certains modèles dans notre dépôt local.
variable "public_replicated_repository" {
type = map(any)
default = {}
}
variable "public_replication" {
type = list(map(any))
description = "local replications"
default = []
}
resource "harbor_project" "local-replicated" {
for_each = var.public_replicated_repository
name = "repl-${each.key}"
public = false
storage_quota = try(each.value.storage_quota, 50)
}
resource "harbor_retention_policy" "local-replicated" {
for_each = var.public_replicated_repository
scope = harbor_project.local-replicated[each.key].id
schedule = "Daily"
rule {
n_days_since_last_pull = 365
repo_matching = "**"
tag_matching = "**"
}
rule {
most_recently_pulled = 10
repo_matching = "**"
tag_matching = "**"
}
rule {
n_days_since_last_push = 30
repo_matching = "**"
tag_matching = "**"
}
}
resource "harbor_replication" "local-replicated" {
for_each = {
for index, replication in var.public_replication :
"${replication.source_registry}->${replication.dest_registry} (${replication.image_name})" => replication
}
name = each.key
action = "pull"
registry_id = harbor_project.public-cache[each.value.source_registry].registry_id
schedule = "0 0/15 * * * *"
dest_namespace = "repl-${each.value.dest_registry}"
dest_namespace_replace = -1
filters {
name = each.value.image_name
}
filters {
tag = try(each.value.image_tag_regex, "**")
}
}
Maintenant que nous avons le code, configurons nos tfvars:
public_replication = [
{
source_registry = "dockerhub"
image_name = "library/traefik"
image_tag_regex = "v2.{10}.{?,??}"
dest_registry = "kubernetes-core"
},
{
source_registry = "dockerhub"
image_name = "fluent/fluent-bit"
image_tag_regex = "2.1.{?,??}"
dest_registry = "kubernetes-core"
}
}
Cela répliquera fluentbit et traefik depuis le Dockerhub vers notre registre local, uniquement pour les versions 2.10.x de traefik et les versions 2.1.x de fluentbit.
Point bonus
Mettre en cache un Artifactory interne pour créer un Harbor-cache distribué global
J’ajoute ici un point bonus, car nous utilisons actuellement Artifactory comme registre de poussée global au travail. L’idée est de donner aux équipes un peu de temps pour migrer vers notre registre de cache global au lieu d’Artifactory, et à un moment les faire migrer complètement vers Harbor.
L’idée est de découvrir tous les dépôts Docker enregistrés dans Artifactory et de créer des dépôts Docker mis en cache dans Harbor
Tout d’abord, configurons la connexion du fournisseur Artifactory :
terraform {
backend "s3" {}
required_providers {
artifactory = {
source = "jfrog/artifactory"
version = "8.4.0"
}
}
}
// Artifactory connection for caching
variable "artifactory_url" {
type = string
default = ""
}
variable "artifactory_registry_domain" {
type = string
}
data "vault_generic_secret" "artifactory_access_token" {
path = local.path_artifactory_access_token
}
provider "artifactory" {
check_license = false
url = var.artifactory_url
access_token = data.vault_generic_secret.artifactory_access_token.data["admin_access_token"]
}
Then create a global read user on Artifactory and discover all repositories:
data "http" "artifactory_packages" {
url = "https://${var.artifactory_registry_domain}/ui/api/v1/ui/repodata?packageSearch=true"
# Optional request headers
request_headers = {
Accept = "application/json"
Authorization = "Basic ${local.artifactory_basic}"
}
}
resource "artifactory_user" "harbor-ro" {
name = local.artifactory_user
password = data.vault_generic_secret.artifactory_access_token.data["harbor_ro_password"]
email = "noreply@veepee.com"
admin = false
profile_updatable = false
disable_ui_access = false
internal_password_disabled = false
groups = ["readers"]
}
locals {
# In another product
path_artifactory_access_token = "secret/<path>/artifactory"
# but it's not so easy
artifactory_user = "harbor-ro"
artifactory_basic = base64encode("${local.artifactory_user}:${data.vault_generic_secret.artifactory_access_token.data.harbor_ro_password}")
# some magic to filter repository list from response
artifactory_repositories_to_replicate = [for v in jsondecode(data.http.artifactory_packages.response_body).repoTypesList : v.repoKey if lookup(v, "repoType") == "Docker" && lookup(v, "isLocal")]
}
Dans l’exemple précédent, nous n’utilisons pas l’URL officielle de l’API Artifactory pour les dépôts car, pour une raison inconnue, nous n’avons pas tous les dépôts, alors qu’en trichant en utilisant l’URL utilisée par l’UI, cela fonctionne bien.
Maintenant, configurons les registres dans Harbor avec leurs politiques de réplication:
// Now configure all registries from artifactory
resource "harbor_registry" "artifactory-docker" {
for_each = {
for index, replication in local.artifactory_repositories_to_replicate :
"${replication}" => replication
}
provider_name = "docker-registry"
name = each.key
endpoint_url = "https://${each.key}.${var.artifactory_registry_domain}"
description = "${each.key} repository from artifactory"
access_id = artifactory_user.harbor-ro.name
access_secret = data.vault_generic_secret.artifactory_access_token.data["harbor_ro_password"]
}
// and the caches
resource "harbor_project" "artifactory-cache" {
for_each = {
for index, replication in local.artifactory_repositories_to_replicate :
"${replication}" => replication
}
name = "cache-${each.key}"
public = false
storage_quota = try(each.value.storage_quota, 50)
registry_id = harbor_registry.artifactory-docker[each.key].registry_id
}
// artifactory cache keeps images pulled in the last 30 days or the 5 most recent images
resource "harbor_retention_policy" "artifactory-cache" {
for_each = {
for index, replication in local.artifactory_repositories_to_replicate :
"${replication}" => replication
}
scope = harbor_project.artifactory-cache[each.key].id
schedule = "Daily"
rule {
n_days_since_last_pull = 30
repo_matching = "**"
tag_matching = "**"
}
rule {
most_recently_pulled = 5
repo_matching = "**"
tag_matching = "**"
}
}
Conclusion
Ce projet était très intéressant et la configuration via API et terraform est très puissante. Nous avons réussi ici à créer des dépôts répliqués multi-datacenter, accessibles via une URL globale et un GSLB, en ajoutant une mise en cache de dépôts externes mais aussi en ayant un chemin permettant aux personnes de migrer en douceur vers notre nouveau registre.
L’une des prochaines étapes est de contribuer au chart officiel pour proposer un autoscaling horizontal des pods comme nous l’avons fait afin de réduire nos correctifs locaux internes.
J’espère que vous avez apprécié cet article, enjoy !